字串失敗機率分析
失敗機率會小於等於 n / P
當 Hash 碰撞發生時,會將不同的字串判斷成相同,機率上限為 n / P。
把字串當成一個多項式
兩個長度 n 的字串 a, b 相等表示兩個多項式 a - b = 0。多項式 a - b 最多會有 n 個根1 ⇒ 失敗機率會小於等於 n / P
字串題目分析一般當成 1 / P
上面分析說 n / P 其實是高估很多的,因為還需要多項式恰好有 n 個根。在一般的情況下,會將不同的字串判斷成相同的機率是 1 / P。
令
若
若
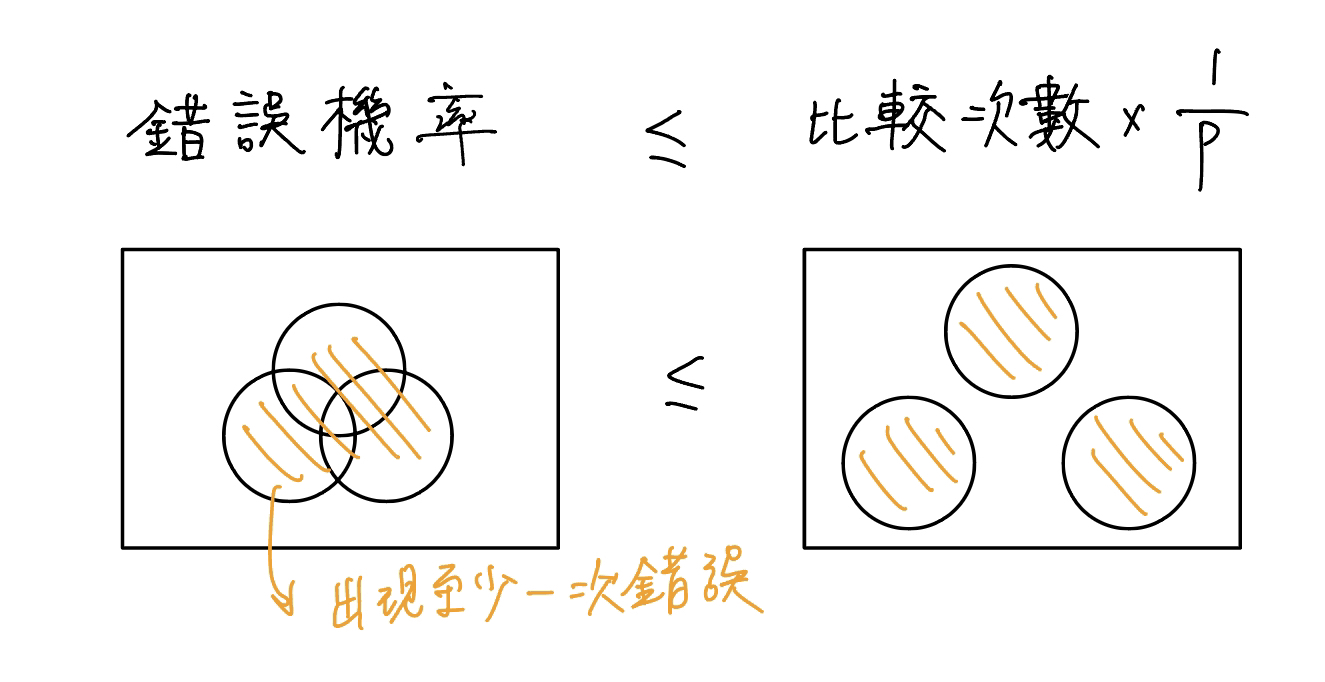
n 次比較錯誤機率 <= n / P
每次比較兩個字串 s, t 是否相同,進行 n 次,會至少出現一次錯誤的機率 <= n / P。
例如我們比較 3 次,一次的失敗機率為 1 / P。我們將圖畫出來 :